
Retrieval-Augmented Generation (RAG) sistemleri son yıllarda yapay zekâdaki gelişimlerle birlikte oldukça olgunlaştı. Embedding modelleri daha iyi hale geldi, reranker katmanları yaygınlaştı ve uzun bağlam pencerelerine sahip modeller sayesinde daha fazla doküman aynı anda işlenebilir oldu. Buna rağmen production seviyesinde çalışan birçok RAG sisteminde performansı belirleyen en kritik katmanlardan biri hâlâ chunking tarafı olmaya devam ediyor.
Bunun nedeni basit. Bir RAG sistemi ne kadar güçlü embedding modeli, ne kadar iyi retrieval pipeline’ı veya ne kadar büyük bir language model kullanırsa kullansın, bilgi sisteme yanlış parçalara bölünmüş şekilde giriyorsa geri getirme kalitesi doğal olarak sınırlı kalır. Başka bir deyişle, retrieval başarısının önemli bir kısmı aslında indexleme anında alınan chunking kararları tarafından belirlenir.
Bu yazıda effective chunking kavramına teknik bir perspektiften bakacağız. Hangi chunking stratejilerinin ne zaman daha iyi çalıştığını, hangi trade-off’ların ortaya çıktığını ve production bir RAG sisteminde doğru chunk yapısını nasıl seçmek gerektiğini inceleyeceğiz.
Chunking Neden Bu Kadar Önemli?
RAG sistemlerinde amaç yalnızca ilgili belgeyi bulmak değildir. Asıl amaç, kullanıcı sorgusunu cevaplamak için gerekli olan en doğru bağlamı, yeterli ama gereksiz olmayan miktarda modele sunmaktır.
İşte chunking burada devreye girer. Çünkü retrieval sistemi çoğu zaman tüm belgeyi değil, belgenin parçalara ayrılmış hâlini arar. Eğer chunk çok küçükse, anlamlı bağlam parçalanır. Eğer çok büyükse, retrieval hassasiyeti düşer ve modele gereksiz bilgi taşınır. Bu da hem recall hem precision tarafında sorun yaratır.
Örneğin, bir teknik dokümantasyonda bir fonksiyonun tanımı bir paragrafta, parametre açıklaması bir sonraki paragrafta, kullanım örneği ise daha aşağıda yer alabilir. Sabit boyutlu ve bağlamı dikkate almayan bir chunking stratejisi bu üç bilgiyi farklı parçalara böldüğünde, sorguya en ilgili chunk geri dönse bile cevap üretmek için gerekli bağlam eksik kalabilir.
Benzer şekilde, bir hukuk metninde veya sözleşmede tek bir madde birkaç paragraf boyunca devam edebilir. Bu yapıyı bozarak yapılan parçalama, semantik bütünlüğü kaybettirir. Sonuç olarak, model doğru bölümü retrieve etse bile yanlış yorumlama riski artar.
Bu nedenle chunking yalnızca bir pre-processing adımı değildir. Retrieval kalitesini, context efficiency’yi, latency’yi ve hatta hallucination oranını etkileyen doğrudan bir mimari karardır.
Chunking İçin Temel Yaklaşımlar
Chunking stratejilerini anlamak için önce kullanılan temel yaklaşımları ayırmak gerekiyor. Günümüzde en yaygın yöntemler birkaç ana kategori etrafında toplanıyor.
Fixed Size Chunking
En basit ve en yaygın yaklaşım sabit boyutlu parçalamadır. Metin belirli bir karakter, kelime veya token sayısına göre bölünür. Uygulaması kolaydır, indeksleme maliyeti düşüktür ve çoğu baseline sistem için hızlı bir başlangıç sağlar.
Bu yaklaşımın popüler olmasının nedeni operasyonel olarak basit olmasıdır. Özellikle heterojen veri kaynaklarında tek tip bir pipeline kurmak gerektiğinde, fixed-size chunking pratik bir çözüm sunar.
Ancak temel zayıflığı da oldukça açıktır. Metnin doğal yapısını dikkate almaz. Paragraf ortasında, tablo açıklamasının içinde veya bir başlığın hemen ardından anlamsız bölünmeler oluşturabilir.
Bu yüzden fixed size chunking çoğu zaman iyi bir başlangıç noktasıdır, ama nadiren en iyi son durumdur.
Overlap Kullanımı
Sabit parçalamada en sık kullanılan iyileştirme overlap eklemektir. Yani her chunk bir önceki parçanın son kısmını kısmen tekrar içerir. Böylece sınırda kalan bilgi tamamen kaybolmaz ve bağlam sürekliliği bir miktar korunur.
Overlap özellikle açıklamanın bir chunkta başlayıp diğerinde devam ettiği senaryolarda faydalıdır. Ancak burada da bir maliyet oluşur. Overlap arttıkça indeks boyutu büyür, benzer içeriklerin retrieval sırasında tekrar tekrar gelme ihtimali artar ve reranking aşamasında redundancy yükselir.
Bu nedenle overlap çoğu zaman kaliteyi artırır ama kontrolsüz kullanıldığında context window verimliliğini düşürebilir.
Recursive veya Structure Aware Chunking
Bu yöntemin temel avantajı semantik bütünlüğü daha iyi korumasıdır. Bir dokümanın section yapısı korunursa, retrieval sonucu gelen chunk hem daha anlamlı olur hem de kullanıcı sorgusuyla daha net eşleşir.
Özellikle teknik dokümantasyon, bilgi bankaları, ürün dokümanları ve akademik metinlerde structure-aware chunking çok daha iyi sonuç verebilir. Çünkü bu tür belgelerde başlık hiyerarşisi yalnızca görsel bir düzen değil, aynı zamanda bilgi organizasyonunun da temelidir.
Ancak burada da dikkat edilmesi gereken bir nokta vardır. Belgenin yapısı her zaman anlamlı olmayabilir. Kötü biçimlendirilmiş PDF’lerde, OCR sonrası bozulmuş belgelerde veya web scraping ile gelen düzensiz metinlerde yapısal ipuçları güvenilir olmayabilir. Yani yapı tabanlı chunking çok güçlüdür ama veri kalitesine oldukça bağımlıdır.
Semantic Chunking
Semantic chunking yaklaşımı, parçalama kararını salt uzunluğa değil anlam değişimine göre vermeye çalışır. Cümle veya paragraf embedding’leri üzerinden konu değişiminin algılanması ve sınırların buna göre çizilmesi bu yaklaşımın temelidir.
Bu yöntem özellikle aynı belge içinde çok sayıda kısa ama farklı konu geçiyorsa oldukça etkilidir.
Buna rağmen, semantic chunking her zaman en iyi seçenek değildir. Çünkü hem pre-processing maliyeti daha yüksektir hem de segmentasyon kararları her zaman stabil değildir.
Dolayısıyla, semantic chunking teorik olarak daha akıllı görünse de, production ortamında dikkatli değerlendirme gerektirir.
Document Specific Chunking
Gerçek dünyada en iyi sonuç veren sistemler çoğu zaman tek bir evrensel chunking stratejisi kullanmaz. Doküman tipine göre farklı chunking mantıkları uygular.
Örneğin, API dokümantasyonu için endpoint bazlı parçalama mantıklıdır. Sözleşmeler için madde bazlı parçalama daha uygundur. Soru-cevap veritabanlarında her ve cevabın tek bir retrieval birimi olması tercih edilebilir. Tablolar için satır bazlı, belge görselleri için ise layout-aware bölme gerekebilir.
Bu yaklaşımın önemi şuradadır: chunking problemi temelde bir bilgi organizasyonu problemidir. Farklı bilgi türleri farklı retrieval birimleri gerektirir. Yani, production seviyesinde güçlü bir RAG sistemi kurmak istiyorsak, önce veri tipini anlamamız gerekir. Chunking stratejisi çoğu zaman model seçiminden önce verilmesi gereken bir karardır.
İyi Bir Chunk’ın Özellikleri Nelerdir?
Etkili bir chunk yalnızca belirli bir boyutta olan parça değildir. Aynı zamanda retrieval için anlamlı ve generation için kullanılabilir bir bağlam birimidir.
İyi bir chunk’ın ilk özelliği semantik bütünlük taşımasıdır. Yani tek başına okunduğunda neyle ilgili olduğu anlaşılmalıdır. Tam anlamı yalnızca komşu chunk’lara bağlı olan parçalar retrieval kalitesini düşürür.
İkinci önemli özellik yeterli özgüllüktür. Chunk çok geniş olursa embedding temsili bulanıklaşır. Özellikle çok farklı alt konuları aynı parçaya koymak retrieval precision’ı azaltır.
Üçüncü özellik ise bağlamsal yeterliliktir. Chunk tek başına anlamlı olmalı ama aynı zamanda kullanıcı sorgusunu yanıtlayacak kadar bilgi de taşımalıdır. Yalnızca başlık içeren veya yalnızca kısa bir cümleden oluşan parçalar çoğu zaman retrieval’de yüzeye çıkabilir, ama generation için yetersiz kalır.
Retrieval Kalitesi ile Chunking Arasındaki İlişki
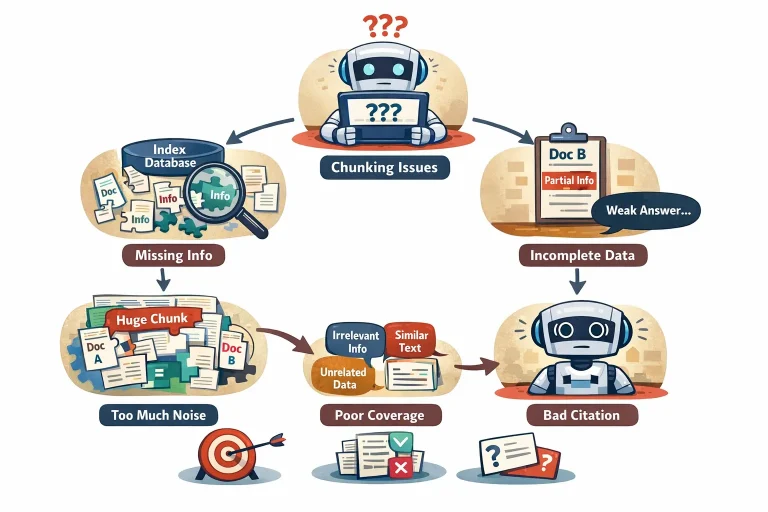
Chunking kalitesini yalnızca kullanıcıya verilen son cevaba bakarak değerlendirmek yanıltıcı olabilir. Çünkü sorun bazen modelde değil, retrieval katmanında başlar.
Yanlış chunking şu problemlere yol açar:
İlk olarak, relevant bilgi index içinde bulunsa bile, retrieval onu yüzeye çıkaramaz. Çünkü gerekli bilgi birden fazla parçaya dağılmıştır ve tek bir chunk yeterli semantik sinyali taşımaz.
İkinci olarak, retrieved chunk doğru belgeye ait olsa bile answerability düşük olur. Yani modelin cevap üretebilmesi için gereken veri eksiktir.
Üçüncü olarak, gereğinden büyük chunk’lar modele çok fazla distractor taşır. Bu durumda model ilgili bilgiyi bağlam içinden ayıklamakta zorlanabilir ve özellikle benzer ifadelerin geçtiği kurumsal belgelerde hata oranı artabilir.
Bu nedenle chunking değerlendirmesi yapılırken yalnızca retrieval hit rate değil, answer coverage ve citation quality gibi metriklere de bakmak gerekir.
Hangi Senaryoda Hangi Chunking Daha Uygun?
Kullanım senaryosu burada belirleyici hale gelir.
SSS, destek merkezi ve ürün dokümantasyonu gibi yapılarda başlık ve paragraf bazlı structure-aware chunking genellikle iyi sonuç verir. Çünkü bilgi zaten modüler şekilde yazılmıştır.
Uzun raporlar, araştırma metinleri ve policy belgelerinde daha büyük ama section temelli chunk’lar daha uygundur. Bu belgelerde anlam birimi çoğu zaman paragraftan daha büyüktür.
Kod, API referansı ve teknik spesifikasyonlarda entity-centric chunking daha etkilidir. Bir fonksiyon, sınıf, endpoint veya konfigürasyon bloğu çoğu zaman tek retrieval birimi olmalıdır.
Sözleşmeler, mevzuat ve hukuki metinlerde madde bazlı ve referans ilişkilerini koruyan chunking stratejileri daha güvenlidir. Çünkü bu tür belgelerde cümle sınırı semantik sınır anlamına gelmeyebilir.
Meeting transcript, çağrı kayıtları veya uzun konuşma dökümlerinde ise time-aware ve topic-aware parçalama daha uygun olur. Sabit boyutlu parçalama burada konuşma akışını bozabilir.
Yazımıza Medium üzerinden de ulaşabilirsiniz.
Yazan: Hayri Yıldız, GenAI Engineer
Fikirlerini paylaş, destek al.
Aşağıdaki iletişim bilgilerinden bize ulaşabilir ve iletişim formumuzu doldurabilirsiniz.
Seba Office Boulevard / İstanbul
Ayazağa Mah. Mimar Sinan Sok. A,
No: 21A İç Kapı No:1 Sarıyer, İstanbul
Levent Office / İstanbul
Yeşilce Mh. Göktürk Cad. Çeşni Sok. No:4 Kat:2 Kağıthane
P: 444 0 885
Ankara
Beştepe, Dumlupınar Blv. No: 10B Yenimahalle / Ankara
P: +90 312 419 43 43
Yardım
Email:
info@treomind.com