
2025 itibarıyla görsel dil modelleri (VLM) artık proof-of-concept (POC) aşamasını geride bırakmış durumda. Görsel kodlayıcıların gelişmesi, daha geniş bağlam pencereleri ve gelişmiş muhakeme yeteneklerinin eklenmesi sayesinde OCR, belge VQA, video analizi ve nesne lokalizasyonu gibi görevler tek bir multimodal model üzerinden çözülebiliyor. Birkaç yıl önce farklı sistemlerin birlikte çözmeye çalıştığı pek çok problem artık tek bir model ve doğal dil talimatlarıyla yönetilebiliyor.
Bu yazıda güncel VLM mimarilerine, 2025 döneminde öne çıkan modellere ve benchmark sonuçlarının ne söylediğine teknik bir perspektiften bakacağız.
Mimari Yaklaşımlar
VLM modellerinin nasıl çalıştığını anlamak için önce kullanılan temel mimari yaklaşımlara bakmak gerekiyor. Günümüzde modeller üç ana mimari yaklaşım etrafında şekilleniyor.
Vision Encoder + MLP Adaptör
Bugün en yaygın kullanılan mimari bu yaklaşım. LLaVA ile popüler hale gelen bu yapıda önceden eğitilmiş bir vision encoder görüntüyü patch embedding dizisine dönüştürür. CLIP veya SigLIP gibi encoder’lar bu görev için sıklıkla kullanılır. Daha sonra bu embedding’ler bir MLP projeksiyon katmanı aracılığıyla LLM’in embedding uzayına aktarılır ve metin tokenlarıyla birlikte modele verilir. Bu mimarinin popüler olmasının nedeni görece basit olması ve mevcut LLM’lerle kolayca entegre edilebilmesidir. Son yıllarda yapılan geliştirmeler de çoğunlukla bu yapıyı daha verimli hale getirmeye odaklanıyor.
Örneğin Qwen2.5-VL modeli [1] her dört vision tokenını tek bir embedding’e sıkıştırarak token maliyetini düşürür. Bu, özellikle yüksek çözünürlüklü görüntülerde önemli bir avantaj sağlar. DeepSeek-VL ise farklı bir optimizasyon kullanır: büyük görüntüler 1024×1024 boyutlarında parçalara bölünerek ayrı ayrı işlenir ve daha sonra sonuçlar birleştirilir.
Qwen2.5-VL, LLaMA 3.2 Vision, PaliGemma 2 ve DeepSeek-VL bu mimariyi kullanan modeller arasında yer alır.
Cross Attention Füzyonu
Bir diğer yaklaşım Flamingo mimarisinden gelen cross attention tabanlı füzyondur. Bu yöntemde görsel embedding’ler doğrudan giriş dizisine eklenmek yerine modelin ara katmanlarına cross attention mekanizması ile enjekte edilir. BLIP-2 modelinde kullanılan Q-Former modülü bu yaklaşımın iyi bilinen bir örneğidir.
Q-Former sabit sayıda öğrenilebilir sorgu embedding kullanarak görsel bilgiyi sıkıştırır ve LLM ile daha kontrollü bir şekilde etkileşime girmesini sağlar.
Bu yöntem token sayısını daha iyi kontrol etmeye yardımcı olur. Ancak eğitim süreci daha karmaşık olduğu için birçok modern model daha basit olan MLP adaptör yaklaşımına yönelmiştir.
Encoder-Free Decoder
Bazı modeller ise tamamen farklı bir yaklaşım dener. Fuyu ve EVE gibi modeller ayrı bir vision encoder kullanmadan ham piksel verisini doğrudan LLM decoder’a verir.
Bu yaklaşım teorik olarak daha esnek görünür çünkü görüntü çözünürlüğü veya encoder sınırlamaları ortadan kalkar. Ancak pratikte eğitim daha yavaş yakınsar ve performans çoğu zaman encoder tabanlı modellere göre daha düşük kalır. Bu nedenle encoder-free mimariler şu anda araştırma tarafında ilgi görse de production sistemlerde daha az kullanılıyor.
Model Karşılaştırması
Bu mimarileri kullanan modeller pratikte nasıl ayrışıyor? Güncel tabloya bakıldığında iki ana grup öne çıkıyor: kapalı kaynak ve açık kaynak modeller.
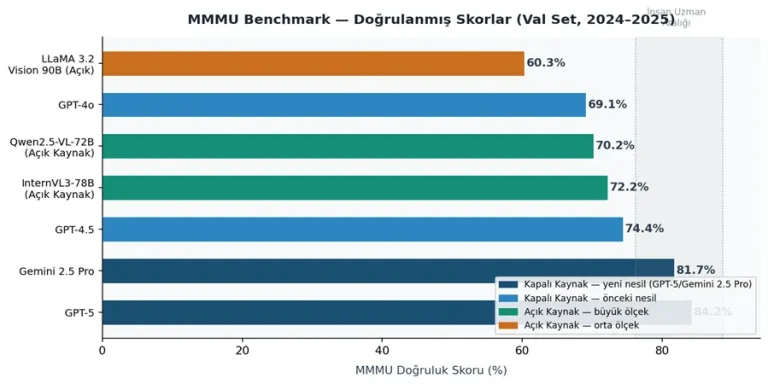
Kapalı Kaynak Modeller
Gemini 2.5 Pro şu anda MMMU’da %81.7 ile [3] en güçlü multimodal modellerden biri olarak kabul ediliyor. Thinking model yaklaşımı sayesinde karmaşık görsel sahnelerde adım adım muhakeme yapabiliyor. Ayrıca bir milyon tokenın üzerinde bağlam penceresine sahip olması uzun belgeler ve video içerikleriyle çalışmayı kolaylaştırıyor.
GPT-5 ise MMMU’da %84.2 ile [7] görsel muhakeme görevlerinde güçlü performans gösteriyor. Buna rağmen bazı benchmark sonuçları modellerin fiziksel dünya anlayışında hâlâ zorlandığını gösteriyor. Özellikle nesne sayma ve rakam tanıma gibi görevlerde hata oranları yüksek kalabiliyor.
Claude 4 modelleri ise farklı bir alanda öne çıkıyor. Özellikle agentic workflow ve computer use senaryolarında güçlü performans sergiliyor.
Açık Kaynak Modeller
Açık kaynak tarafında ise son iki yılda oldukça hızlı bir gelişim yaşandı. Qwen2.5-VL modelleri [1] dynamic resolution işleme, video input desteği ve çok dilli kullanım gibi özellikleriyle dikkat çekiyor. Özellikle 72B versiyonu MMMU’da %70.2 ile birçok benchmarkta kapalı kaynak modellere oldukça yakın sonuçlar elde ediyor.
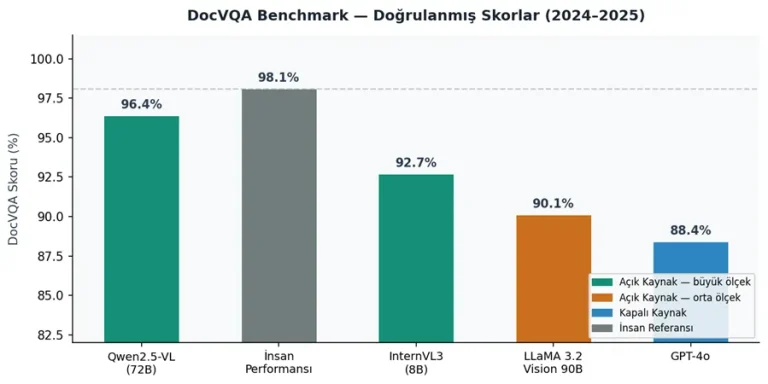
LLaMA 3.2 Vision modeli [5] özellikle belge işleme ve OCR görevlerinde güçlü performans sunuyor. Structured data extraction ve document VQA gibi kurumsal kullanım senaryolarında sık tercih ediliyor.
Gemma 3 daha küçük ölçekli ancak oldukça verimli modeller sunuyor. Pan and Scan yöntemi sayesinde farklı boyutlardaki görüntüler dinamik şekilde işlenebiliyor. GLM-4.5V modeli MoE mimarisi kullanıyor ve spatial reasoning görevlerinde oldukça güçlü sonuçlar veriyor. Toplam 106 milyar parametreye sahip olsa da aktif parametre sayısı çok daha düşük.
DeepSeek-VL ise özellikle düşük kaynaklı ortamlarda dikkat çekiyor. Sadece 1.3 milyar aktif parametre kullanmasına rağmen bilimsel muhakeme görevlerinde oldukça iyi sonuçlar verebiliyor.
InternVL3–78B ise MMMU benchmarkında %72.2 ile [4] açık kaynak modeller arasında en güçlü seçeneklerden biri olarak öne çıkıyor.
Benchmark Sonuçları Ne Söylüyor?
Farklı benchmarklar multimodal modellerin farklı yeteneklerini ölçer. MMMU gibi benchmarklar fizik, kimya ve mühendislik gibi alanlarda expert level multimodal reasoning ölçerken, Video-MME gibi benchmarklar video anlama ve temporal reasoning yeteneklerini değerlendirir.
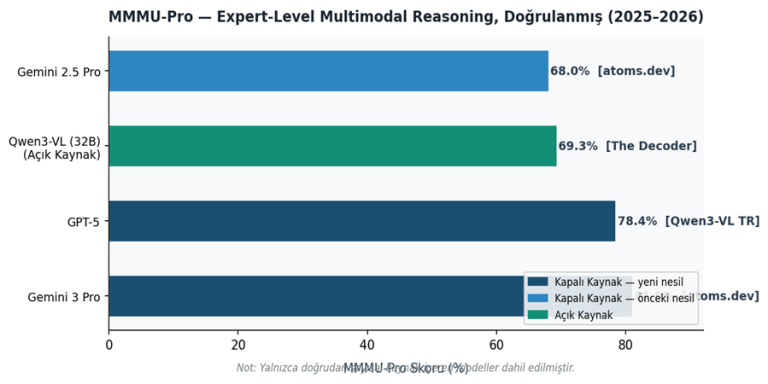
PhysBench gibi benchmarklar ise modellerin fiziksel dünya anlayışını ölçmeye çalışır. Bu benchmarklar ilginç bir noktayı ortaya koyuyor: model boyutu büyüdükçe algılama performansı artıyor; ancak muhakeme yeteneği aynı hızda gelişmiyor.
UniBench sonuçları da benzer bir tablo gösteriyor. Daha büyük modeller daha iyi algılama yapabiliyor ancak güçlü reasoning için daha kaliteli veri ve daha iyi eğitim stratejileri gerekiyor.
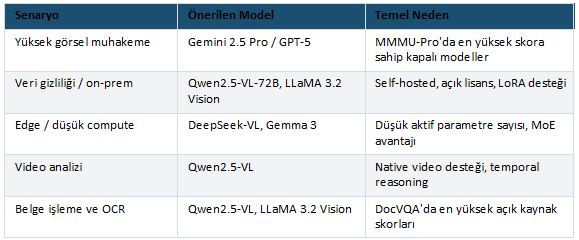
Kullanım Senaryosuna Göre Model Seçimi
Gerçek dünyada model seçimi yalnızca benchmark skorlarına bakarak yapılmamalıdır. Kullanım senaryosu çoğu zaman model seçiminde daha belirleyici olur.
Açık Kaynak ve Kapalı Kaynak Arasındaki Fark Daralıyor
Son yıllarda açık kaynak ve kapalı kaynak modeller arasındaki performans farkı giderek azalıyor. Bunun önemli nedenlerinden biri MoE mimarilerinin yaygınlaşmasıdır.
Örneğin Qwen3–235B modeli toplam 235 milyar parametreye sahip olmasına rağmen yalnızca 22 milyar parametreyi aktif kullanır. Bu sayede dense modellere yakın performansı çok daha düşük inference maliyetiyle sunabilir.
Benzer şekilde Kimi-VL-A3B-Thinking modeli de oldukça düşük aktif parametre sayısıyla güçlü multimodal reasoning performansı elde edebiliyor.
Açık kaynak modeller ayrıca fine-tuning açısından da büyük avantaj sunar. LoRA gibi parametre verimli yöntemler sayesinde domain-specific modeller çok daha düşük maliyetle eğitilebilir.
Kapalı kaynak modeller ise daha büyük context window’lar, daha gelişmiş güvenlik filtreleri ve bazı karmaşık reasoning görevlerinde hâlâ daha yüksek performans sunabiliyor.
Sonuç
Görsel dil modelleri hızla gelişiyor ve multimodal yapay zekâ sistemlerinin merkezine yerleşiyor. Ancak doğru modeli seçmek yalnızca benchmark skorlarına bakmakla mümkün değildir. Lisanslama modeli, deployment senaryosu, fine-tuning ihtiyacı, multimodal giriş desteği ve inference maliyeti birlikte değerlendirilmelidir.
Sonuç olarak en doğru model her zaman en büyük model değildir. En iyi seçim, ihtiyaç duyulan performans ile maliyet arasındaki en dengeli noktayı sunan model olacaktır.
Yazımıza Medium üzerinden de ulaşabilirsiniz.
Yazan: Zelal Akyol, AI Engineer
Kaynaklar
[1] Qwen Team (2025). Qwen2.5-VL Technical Report. https://arxiv.org/abs/2502.13923
[2] vals.ai (2025). MMMU Benchmark Leaderboard. https://www.vals.ai/benchmarks/mmmu
[3] DataCamp / Helicone (2025). Gemini 2.5 Pro — MMMU %81.7. https://www.datacamp.com/blog/gemini-2-5-pro
[4] Zhu, W. ve ark. (2025). InternVL3 Technical Report. https://arxiv.org/abs/2504.10479
[5] aimlapi.com (2025). LLaMA 3.2 90B Vision vs GPT-4o. https://aimlapi.com/comparisons/llama-3-2-90b-vision-vs-gpt-4o-vision
[6] Fu, L. ve ark. (2025). OCRBench v2. https://arxiv.org/abs/2501.00321
[7] AIbase (2025). GPT-5 — MMMU %84.2. https://www.aibase.com/news/20345
[8] The Decoder (2025). Qwen3-VL — MMMU-Pro %69.3. https://the-decoder.com/qwen3-vl
[9] atoms.dev (2025). Gemini 3 Pro — MMMU-Pro %81. https://atoms.dev/blog/2025-llm-review
[10] CometAPI (2026). GPT-4.5 — MMMU %74.4. https://www.cometapi.com/gpt-4-5-vs-gemini-2-5-pro
Fikirlerini paylaş, destek al.
Aşağıdaki iletişim bilgilerinden bize ulaşabilir ve iletişim formumuzu doldurabilirsiniz.
Seba Office Boulevard / İstanbul
Ayazağa Mah. Mimar Sinan Sok. A,
No: 21A İç Kapı No:1 Sarıyer, İstanbul
Levent Office / İstanbul
Yeşilce Mh. Göktürk Cad. Çeşni Sok. No:4 Kat:2 Kağıthane
P: 444 0 885
Ankara
Beştepe, Dumlupınar Blv. No: 10B Yenimahalle / Ankara
P: +90 312 419 43 43
Yardım
Email:
info@treomind.com